RICE has a division sign in it. For fifteen years that division sign did the heavy lifting. You divided reach times impact times confidence by effort, and effort was the number that separated the cheap wins from the expensive bets. It was the brake on a backlog full of good ideas.
That brake is failing. When a coding agent ships a working feature in an afternoon and a PM builds a clickable flow in Lovable before lunch, the effort estimate on most backlog items drops toward one or two person-weeks. Sometimes person-hours. Divide by a number that small and almost everything scores high. The formula stops ranking. It just shrugs.
The fix is not to abandon prioritization. It's to swap out the denominator. Building was never the only cost; it was the one cost large enough to dominate the math. Now that it shrank, the costs that were always there finally show up: user attention, maintenance, and the quality work that keeps an AI feature honest.
Why the effort denominator quietly stopped working
RICE assumes effort is the scarce resource. The whole point of dividing by it was to punish features that ate weeks of engineering for a thin payoff. When two features had the same reach and impact, the cheaper one won. That ranking held because building was genuinely hard and slow.
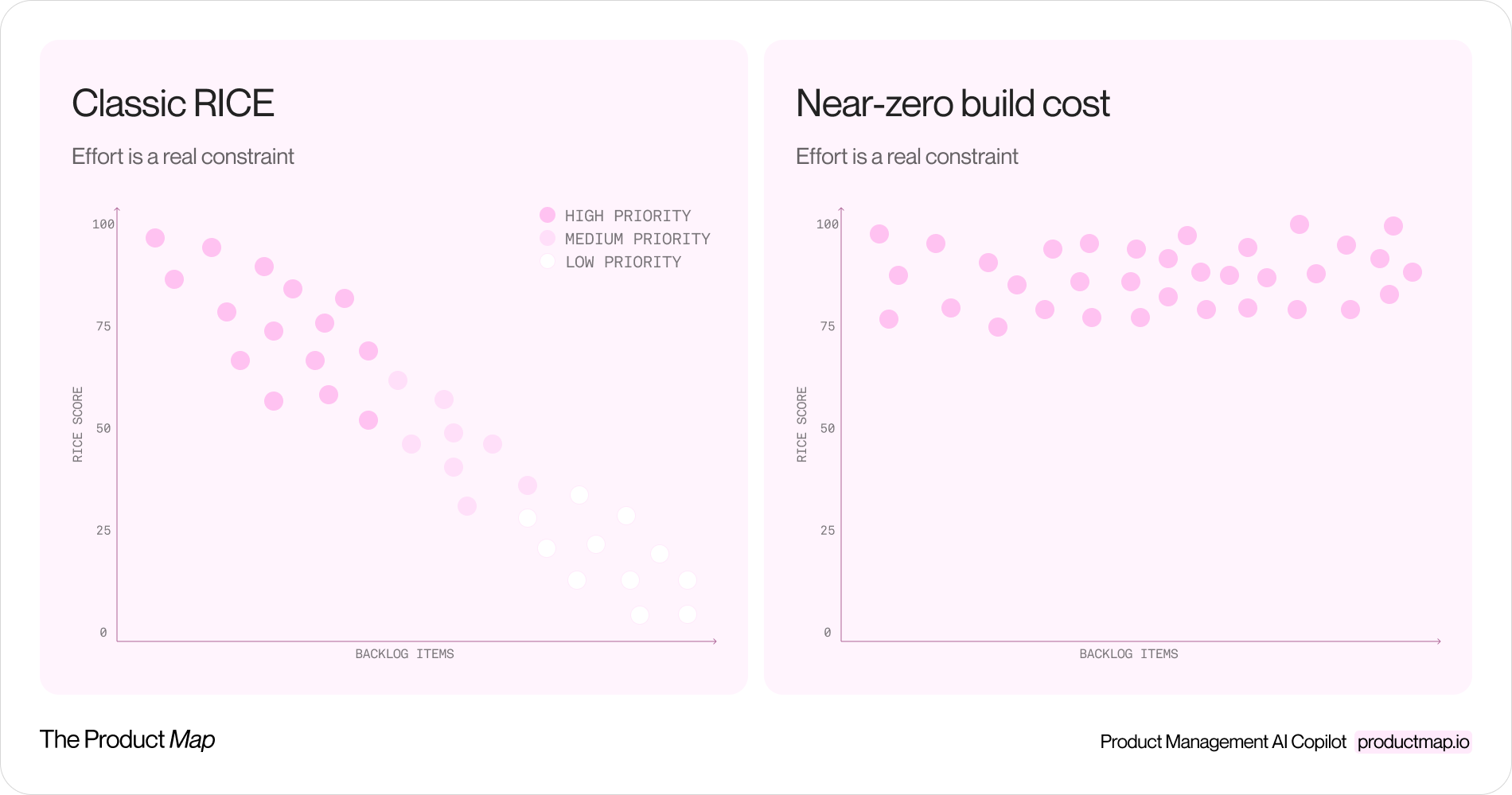
Coding agents broke the assumption. Engineering output at teams using agents roughly tripled in 2026, and prototyping tools let non-engineers produce real interfaces with no one in the loop. The effort column on your scoring sheet now reads 0.5 or 1 for items that used to read 5 or 8.
Watch what happens to the math. A feature with a numerator of 4,000 and an effort of 8 scored 500. The same feature at effort 1 scores 4,000. Every item inflates, and they inflate unevenly based on rough guesses about how fast an agent will move. The ranking you get out is noise dressed up as precision.
When the denominator trends toward zero, small errors in the estimate produce huge swings in the score. A formula that was stable for a decade becomes a random number generator the moment building gets cheap.
This is the trap. Teams keep filling in the effort column out of habit, trust the ranked output, and quietly ship whatever an agent could build fastest instead of whatever the business needed most. The tool still produces a number. The number stopped meaning anything.
The new scarce inputs: attention, upkeep, and eval cost
If effort is no longer the constraint, name the constraints that are. Three of them were always in the system, hidden behind the cost of building.
The first is user attention. Every feature you ship competes for the same finite space in a user's head and a product's surface area. Cheap to build does not mean free to adopt. A bloated product with forty half-used features costs your users more than it costs you, and no agent makes that cost go away.
The second is maintenance load. Code that took an afternoon to generate still has to be monitored, debugged, secured, and updated for years. AI-generated code arrives faster but not cleaner, and someone owns it the moment it ships. The build was the down payment. Maintenance is the mortgage.
The third is quality and eval cost, and it's specific to AI features. A non-deterministic feature needs an eval set, guardrails, and ongoing review to keep it from drifting. Every model-powered feature also carries a per-interaction inference cost that hits your unit economics on every active user. The more people love it, the more it costs to run.
None of these shrank when building got cheap. They became the whole story.
Reworking the RICE formula for near-zero build cost
Keep the numerator. Reach, impact, and confidence still describe the value of a bet, and that part of prioritization hasn't changed. Replace effort with a denominator that captures what actually constrains you now. Call it drag.
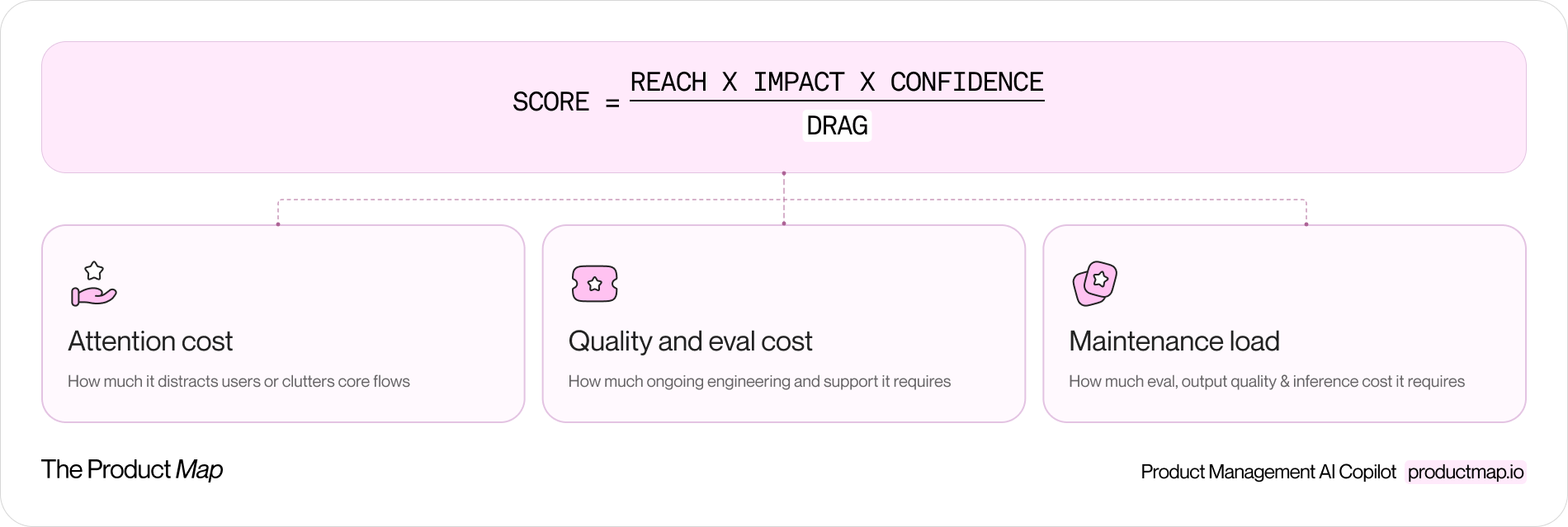
Drag is the ongoing cost of having shipped, scored on a simple scale. It rolls up three factors:
- Attention cost: how much it adds to the product's surface area and steals from the user's focus. A feature that clutters a core flow scores high. A quiet improvement to something users already do scores low.
- Maintenance load: how much ongoing engineering, monitoring, and support the feature demands after launch. Anything touching billing, auth, or data integrations scores high. A static page scores low.
- Quality and eval cost: for AI features, the size of the eval set, the risk of bad output, and the per-interaction inference bill. A feature that gives financial advice scores high. An internal draft generator with a human reviewer scores low.
The formula becomes value over drag instead of value over effort:
Score = (Reach × Impact × Confidence) / Drag
Score each drag factor 1 to 3, then sum or average them into a single denominator. The exact scale matters less than the shift in what you're measuring. You stop rewarding features for being easy to build and start penalizing them for being expensive to live with. That is the reorder that brings the ranking back to life.

The maintenance tax that nobody puts in the score yet
Here's the part most prioritization advice skips, and it's the one a head of product feels before anyone else. Cheap building doesn't reduce your total cost. It moves the cost from a one-time build into a permanent tax, and it hides the tax behind the speed.
Every feature you ship is a liability you carry forever. It needs to keep working when the model changes, when the API deprecates, when a dependency breaks, and when a user finds the edge case your eval set missed. Ship three times as many features because building is cheap, and you've tripled that standing liability without tripling the team that maintains it.
This is how products rot in 2026. Not from moving too slow. From shipping everything that was easy to ship, accumulating a maintenance backlog that no one scored, and watching the team's velocity drain into keeping the pile alive. The afternoon prototype that became production is now a thing someone pages about at 2 a.m.
The discipline that used to come free, enforced by the sheer cost of building, now has to be a deliberate choice. Saying no got harder precisely because saying yes got cheaper. A revised score makes the tax visible at decision time, before it compounds. Reflecting that restraint on the roadmap is the senior move most teams skip.
A revised scoring example you can copy this quarter
Take two features competing for the next sprint.
Feature A is an AI summary that auto-condenses every thread in a shared inbox. Reach is 8,000 users a quarter, impact is 2, confidence is 0.8. Numerator: 12,800. Under classic RICE at an effort of 1 person-month, it scores 12,800 and wins easily.
Feature B is a manual setting that lets a team pin three saved filters. Reach is 2,000, impact is 1, confidence is 1. Numerator: 2,000. At an effort of 0.5, classic RICE scores it 4,000. It loses.
Now score drag. Feature A carries a real inference bill on every summary, needs an eval set so it doesn't hallucinate a thread's content, and adds a prominent element to a core screen. Attention 3, maintenance 3, eval cost 3, drag of 9. Revised score: 12,800 / 9 = 1,422.
Feature B is deterministic, touches no model, and tucks into an existing menu. Attention 1, maintenance 1, eval cost 1, drag of 3. Revised score: 2,000 / 3 = 667.
Feature A still wins, and it should. But the gap collapsed from 3x to roughly 2x, and the 9 in its denominator is now a visible warning that this feature commits you to a recurring cost. Run a third, cheaper AI feature through the same sheet and watch it land below the boring filter feature once its drag is honest. That reordering is the entire point.
What to change before your next planning cycle begins
Open your current scoring sheet and look at the effort column. If most items now read 1 or below, the column is no longer ranking anything, and the order it produces is an artifact of guesswork.
Replace it with a drag score built from attention, maintenance, and eval cost. Keep the numerator you trust. Re-rank the backlog once with the new denominator, or hand the sheet to the backlog prioritization agent and let it score drag with you, then note every item that moved. The features that fell are the ones you were about to ship because they were easy, not because they were worth carrying.
Building costs almost nothing now. Living with what you built costs more than ever. Score the thing that's actually scarce.