A classic PRD answers one question: what should we build? For fifteen years that was enough. The PM described a feature, an engineer built exactly that, and the output was the same every time a user clicked the button.
An AI agent breaks that contract. It doesn't wait for an engineer to translate intent into deterministic code. It reads context, decides, and acts on its own, and it produces a different output on two identical runs. The moment your product includes an agent, the old PRD stops describing what will actually happen in production.
Most teams notice this too late. They ship an agent spec that reads like a feature spec, then discover in week two that nobody wrote down what the agent is allowed to do without a human in the loop. This guide shows how the PRD changes for agentic features, and the one section every agent spec needs that no feature spec ever had.
Why an agent breaks the classic PRD
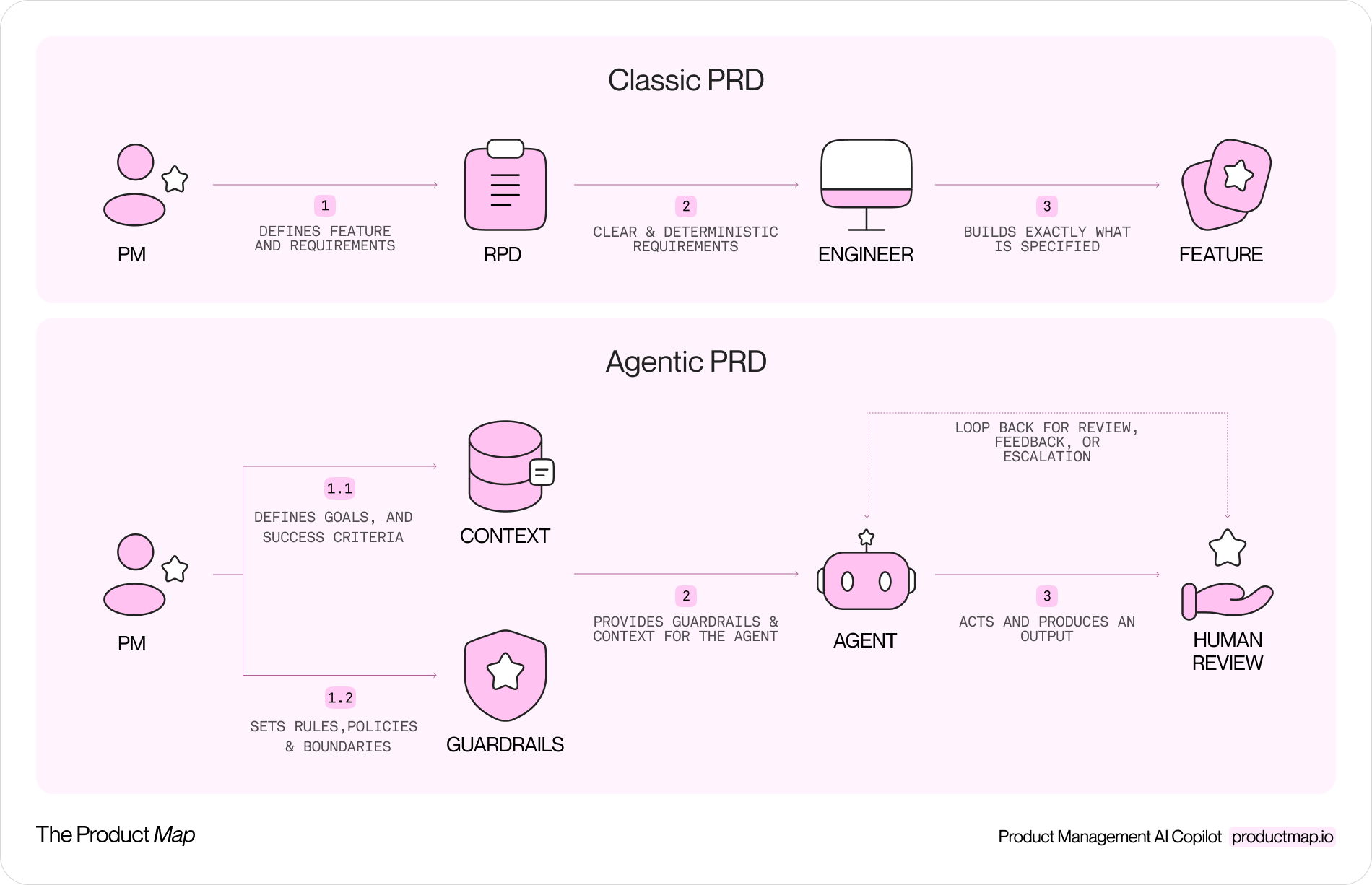
A feature is deterministic. Given the same input, it returns the same output, so a PRD can describe it fully by listing inputs, outputs, and edge cases. You write it down once and the behavior is fixed.
An agent is not deterministic. It interprets a goal, chooses from a set of actions, and its path varies with the model, the context, and the phrasing of the request. You can't enumerate every output because you don't control every output. What you control instead is the boundary: what the agent may touch, where it must stop, and what happens when it gets something wrong.
That shift changes the center of gravity of the document. A feature PRD spends most of its words on what the thing does. An agent PRD spends most of its words on what the thing is allowed to do, and who steps in when the answer is no.
A bug in a feature breaks one screen. A poorly bounded agent issues a refund, emails a customer, or deletes a record, and it does it at machine speed across every session at once. The blast radius is the difference.
From spec to context: what the agent reads
There's a popular claim that the PRD is dead. It isn't. The handoff target changed. A feature PRD is read by an engineer who fills the gaps with judgment. An agent PRD is read, in part, by a model that fills the gaps with whatever is in its context window.
So the document splits into two jobs. The first job is still human: align the team on the problem, the user, and the success metric. The second job is new: assemble the context the agent reads at runtime. That second part is closer to context engineering than to spec writing. You decide which facts the agent gets, which constraints bind it, and what it should ignore.
Treat these as distinct layers in the same document:
- Intent layer: the problem, the user, the goal, and how you'll measure success. This is the part a stakeholder reads to approve the work.
- Context layer: the data, tools, and ground truth the agent reads on every run. Vague context produces confident, wrong output, so this layer is specific or it's useless.
- Boundary layer: the guardrails. What the agent may do alone, what needs a human, what gets logged, and who gets paged.
The intent layer is familiar. The context layer is where most teams underinvest. The boundary layer is the one almost everyone forgets, and it's the one that determines whether the feature is safe to ship.
The guardrails section every agent spec needs
This is the section a feature PRD never had. Write it for every agentic feature, no matter how small the scope looks on day one. Four questions, answered plainly.
Take a concrete example: a support agent that reads an incoming ticket, drafts a reply, and can issue a refund. Each question below has a real answer for that agent.
Permissions: what the agent may do alone
List the actions the agent can take without asking. Be explicit about the verbs. Our support agent may read the ticket, read the order history, draft a reply, and tag the conversation. Name the boundaries in the same breath: it may draft a refund but not send one above twenty dollars. The default for anything unlisted is no.
Human approval: where it must stop
Define the gates. A gate is any action where the agent prepares the work but a person commits it. For the support agent, sending a reply to an angry customer and issuing any refund over twenty dollars are gates. Write the threshold as a number, not an adjective. "High-value refunds need approval" is not a spec. "Refunds over twenty dollars route to a human" is.
Logging: what gets recorded
Specify what the agent writes down on every run: the input it received, the context it read, the action it chose, and the reasoning if the model exposes it. You need this for two reasons. When the agent does something wrong, the log is how you find out why. When a customer disputes an outcome, the log is your record of what happened.
Escalation: who gets paged
Name the owner. When the agent hits a case it can't handle, or its confidence drops below a threshold, or it fails an action, someone has to catch it. Write down who, and how fast. An agent with no escalation owner is an agent that fails silently, and silent failure in production is the worst outcome on this list.

Defining done when output varies run to run
Acceptance criteria assume a fixed output. Click here, see that. An agent has no fixed output, so "the agent writes a good reply" is not testable. You need a different definition of done, and it looks like an evaluation set, not a checklist.
Build a small set of real cases the agent must handle. Ten to twenty is enough to start. For each case, write the input, the context, and what a good outcome looks like, then grade the agent's output good or bad against that. This is your golden set, and it's how you measure quality before launch and catch regressions after.
Tie the set to the success metric from your intent layer. If the goal is faster ticket resolution without a drop in customer satisfaction, your cases test both: did the agent resolve the ticket, and would a reasonable customer accept the reply. Track those numbers the way you'd track any product metric, and treat a failing eval as a blocker, not a nice-to-have.
The criteria have to be specific or the evaluation is theater. "Did the agent answer the question" beats "is the response high quality," because two reviewers will agree on the first and argue about the second.
Start with the guardrails, not the features
Here's the reorder that saves teams the most pain. Write the boundary layer first. Before you describe what the agent does, describe what it's allowed to do and where it stops. The capabilities you're comfortable shipping fall out of the guardrails you can defend, not the other way around.
That order also forces an honest conversation early. When you write "this agent can send emails to customers without review," someone in the room will push back, and that pushback belongs in the spec phase, not in a postmortem. Guardrails first turns a scary feature into a scoped one.
If you want a structured starting point, Product Map's PRD agent drafts the intent and context layers and prompts you for the guardrails section so the boundary work doesn't get skipped. Use it to get a first draft on the page, then spend your judgment where it counts: on the thresholds, the gates, and the escalation owner. Those four answers are the difference between an agent you can ship and one you'll be unwinding in production.